Is AI winter coming?
Note: Three days ago, OpenAI published o1, a new model trained to excel at complex reasoning tasks. On benchmarks purporting to measure this, it indeed blows previous models out of the water and early testing seems to confirm that it is indeed a vast improvement. While, as usual, the announcement was light on technical details, the prevalent hypothesis is that OpenAI somehow generated (either synthetically or through expert annotations) a large number of chain-of-thought reasoning examples and, incorporating reinforcement learning, fine-tuned their model on this. This announcement was completely unexpected to me, I hadn't expected chain-of-thought to work this well and this significantly changes my views on AI progress. Still, I am mostly finished with this article and will publish it as it had been my assessment of future LLM progress for roughly a year.
One and a half years ago, GPT-4 was announced. Published by OpenAI only a couple of months after its predecessor GPT-3.5, the large language model (LLM) far surpassed all other systems of its kind, becoming the most apt conversational system on the planet. While previous systems were mainly template-based ELIZA-style chatbots, the GPT series was able to emulate human language almost perfectly and write coherently even for thousands of words.
These releases sparked a myriad of reactions. Software dinosaurs like Google, perceiving the asteroid's shadow, scrambled to train their own models while commenters on internet forums such as r/singularity prophesized a glorious future where all the boring work would be automated by intelligent but soulless machines, given us the opportunity to write books, compose symphonies and get addicted to videos games. In my specific corner of the internet, the Rationality/Effective Altruism spheres, the reactions were markedly different. Instead of joy, the new models caused fear, resulting in posts such as Bing chat is the AI fire alarm (Bing Chat being an early release of fine-tuned GPT-4 version). People worried that with further that the architecture for general intelligence had been found and that with more scaling[1] a smarter and more capable species would arise that will replace humans. Rather than remaining loyal to its human creators, an AI could develop a will of its own, striving for greater things than what humanity had planed for it and disposing of its godfather species in the process. So great was the fear that in March 2023, an open letter was signed by a range of prominent figures in AI, such as Yoshua Bengio, Stuart Russell and Elon Musk, who demanded a six month pause for training an AI system more powerful than GPT-4. The AI labs didn't like this. They absolutely promised that they would put safety first, but that a flimsy letter couldn't stop them from putting out the smartest, most advanced model in the world.
The funny thing is that after making these declarations, not a single company actually bothered to put out a better model. Now, one and a half years later, there have been some very modest improvements, which I attribute mostly towards a mix of benchmarking hacking, improvements in prompting and post-training. While the best models today, such as Claude Sonnet 3.5, GPT-4o, Gemini 1.5 Pro and Llama 3.1, are a bit easier to use than the first version of GPT-4, they do not feel fundamentally more intelligent. Early on, critics of LLMs had pointed out various flaws in the models, most of which have been unsolved to this day. There still seems to be no solution for hallucinations as models frequently make up facts and their output can not generally be trusted. Out-of-domain generalization remains a prevailing problem of the transformer architecture, which is only masked by the fact that SOTA models are trained on the entire internet and have soaked up large amounts of niche knowledge. Still, some basic tasks such as figuring out a way to ferry two chickens across a river in a boat which can carry both of them allude them, if the question matches a commonly used riddle (in this case, in the riddle there are fewer spots than animals). See, e.g. below the output of the latest GPT-4o-mini model.
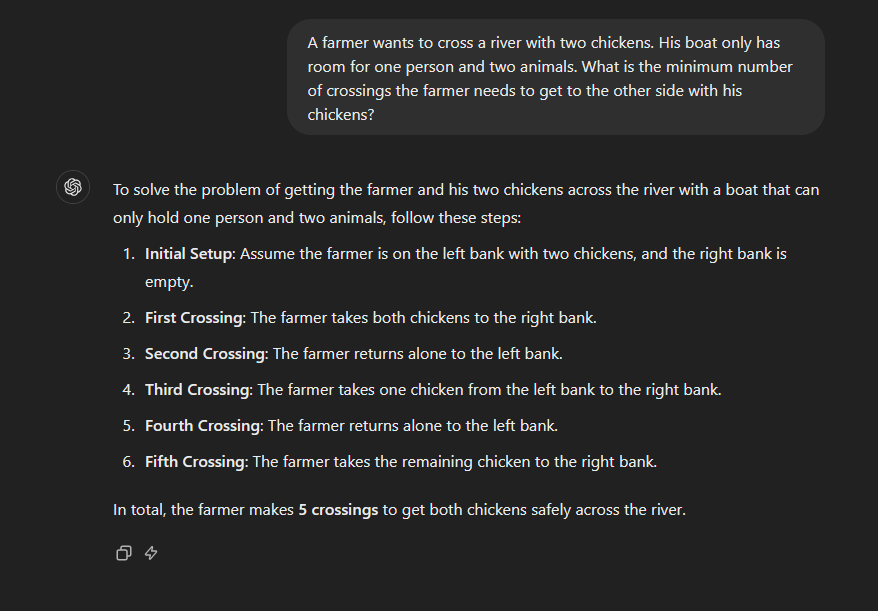
The only issue, where I feel like AI has made significant progress is in terms of context windows (the number of words or "tokens" the model can remember). While the early models were limited to a couple of thousand, recent Google models can ingest millions of words. Still, long context windows do not help if the models make stuff up and elicit failures of basic reasoning.
Why has no better model been developed? There are a couple of competing hypotheses, the one that feels most plausible too me is that the current problems are simply inherent to the transformer architecture and its training regime. This would mean that no simple tricks or simply training the models longer on more data would alleviate their current faults and new architectures would have to be found.
For an explanation of the scaling hypothesis, I can recommend this excellent post by Gwern. ↩︎